开题
3年前写爬虫的时候还是用的正则,而且都是用原生的库。最近貌似爬虫相关的文章比较多,于是我也想弄点资料玩一玩了。简单看了下scrapy的使用,发现用了xpath来定位爬取数据,确实比正则要简介方便。
但是在我进行页面分析的时候,发现网上居然没有xpath在线测试的工具,json格式化,正则测试,unix时间戳什么的倒是不少,于是花了一点时间做了一个很简单的网页版xpath在线测试,这样在对html进行分析的时候就方便多了。
xpath介绍
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
因此,对 XPath 的理解是很多高级 XML 应用的基础。
最后
实际代码非常少,寥寥几十行就可以了,演示效果如下:
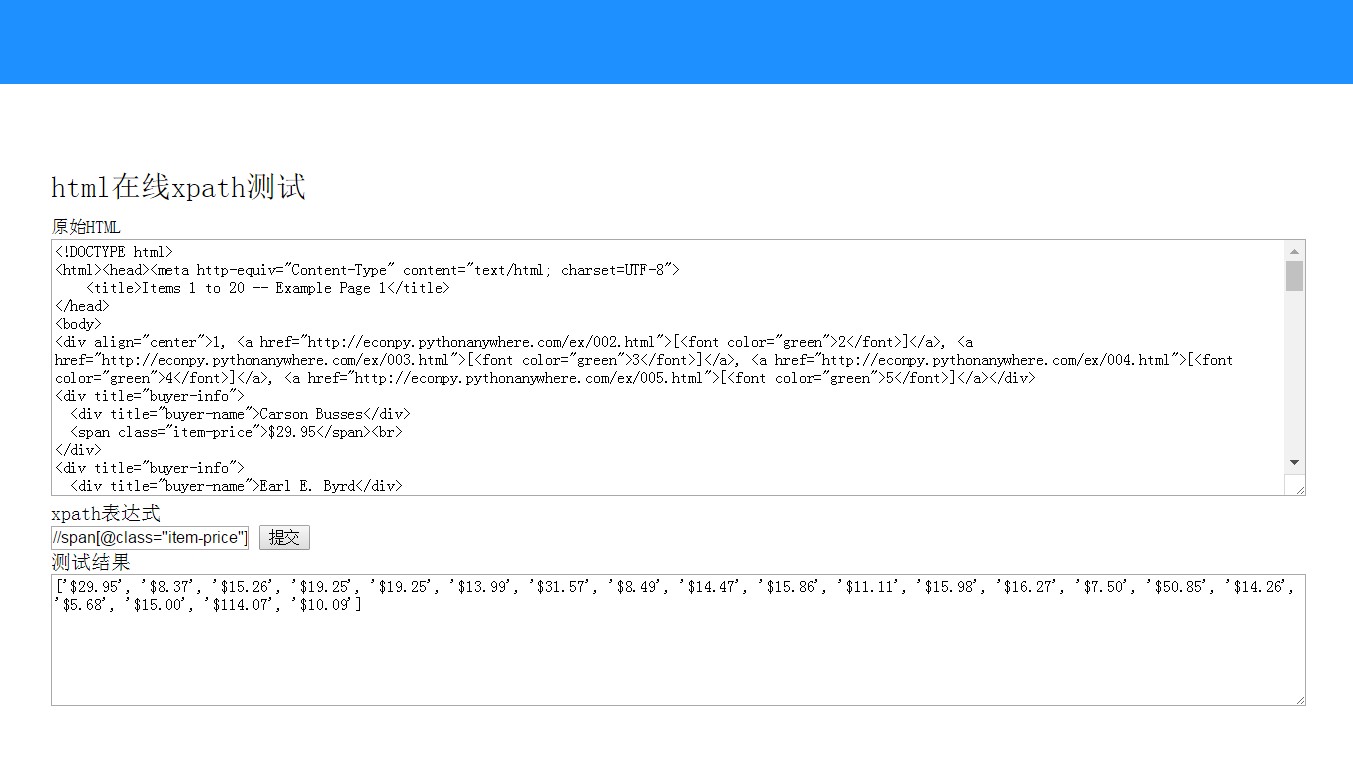
xpath_tester:源码地址
至于前端效果就先不管那么多,还得抓紧时间爬数据呢。。。